Multi-Cloud Support
Deploy across many clouds via the Infrastructure Manager (IM).
A flexible Virtual Research Environment (VRE) to run Docker-based, compute-intensive workloads with serverless workflows on elastic Kubernetes clusters deployed across multiple clouds.

Deploy across many clouds via the Infrastructure Manager (IM).
Kubernetes clusters scale up and down automatically based on workload.
Compose data-driven serverless workflows with the Functions Definition Language.
Built on Kubernetes components for easier extension and integration."
Apache 2.0 License, also available as a managed SaaS.
Runs on ARM-based edge devices (e.g., Raspberry Pi and NVIDIA Jetson Nano).
Reduces idle resource usage by scaling services down depending onn the workload.
Tracks service status and metrics. Enforces quota allocations.

OSCAR provides data-driven serverless computing for data-processing applications. Services can be triggered by file uploads to an object storage backend, executing a user-defined shell script inside a container based on a user-defined Docker image. Executions are orchestrated as Kubernetes batch jobs, and output data can be uploaded to supported object storage backends. Synchronous invocations with scale-to-zero support and exposed services for those who provide APIs are also available.
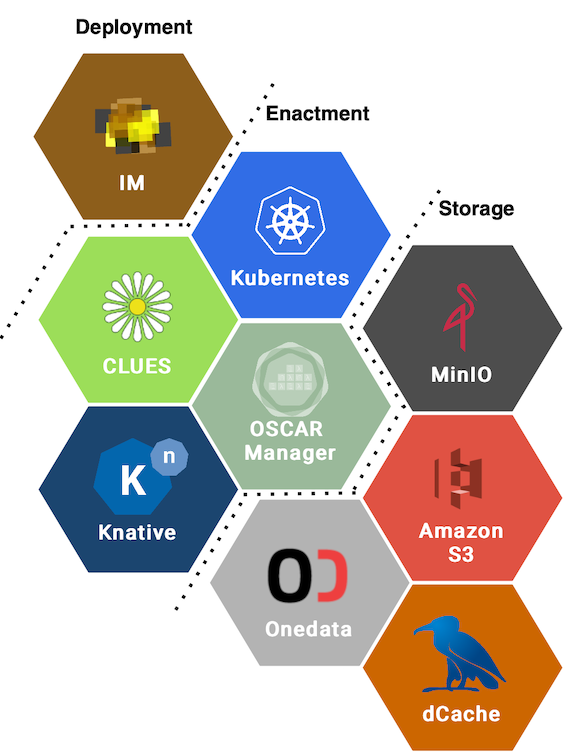
Each OSCAR cluster includes MinIO so file uploads can trigger data-processing applications. Services can be chained to build data-driven workflows. Output storage also supports other backends, including Amazon S3 and EGI DataHub (based on Onedata).
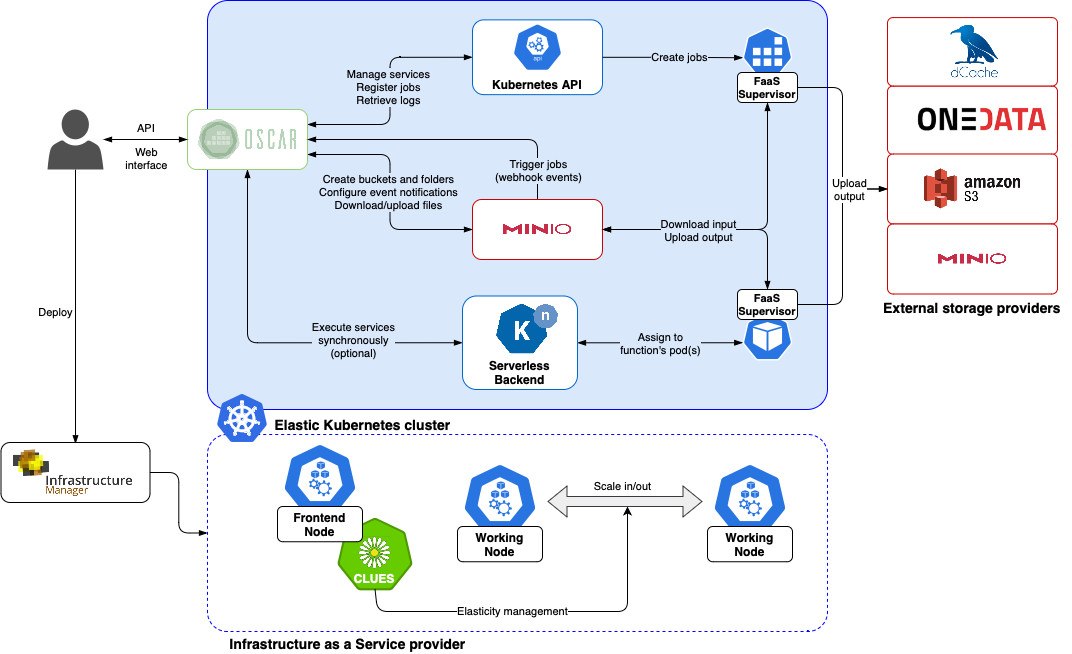
An OSCAR cluster is built on dynamically deployed, elastic Kubernetes infrastructure. With the CLUES elasticity system, clusters self-adapt to incoming workload by scaling node capacity up to the deployment limits you define.
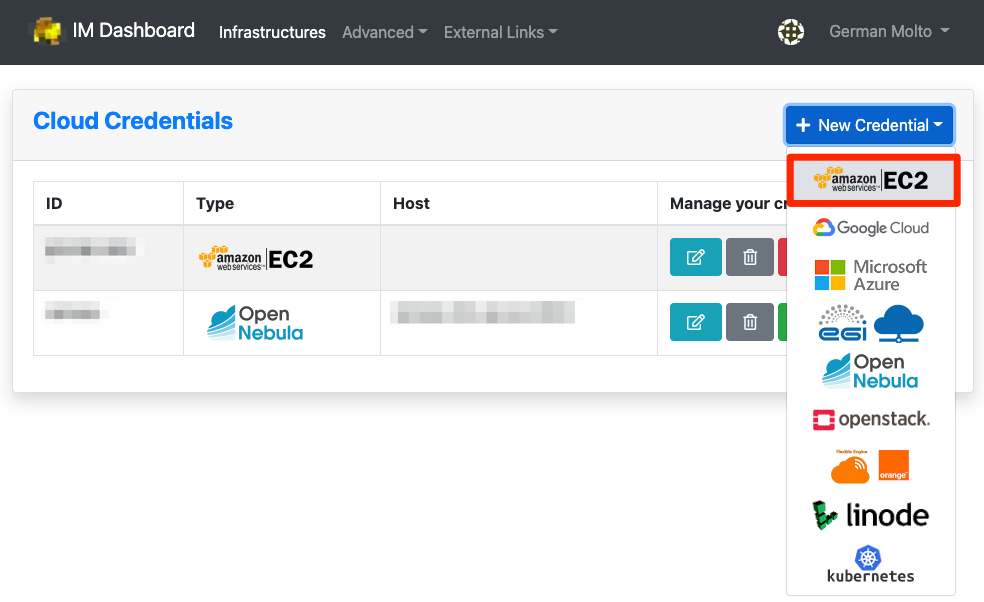
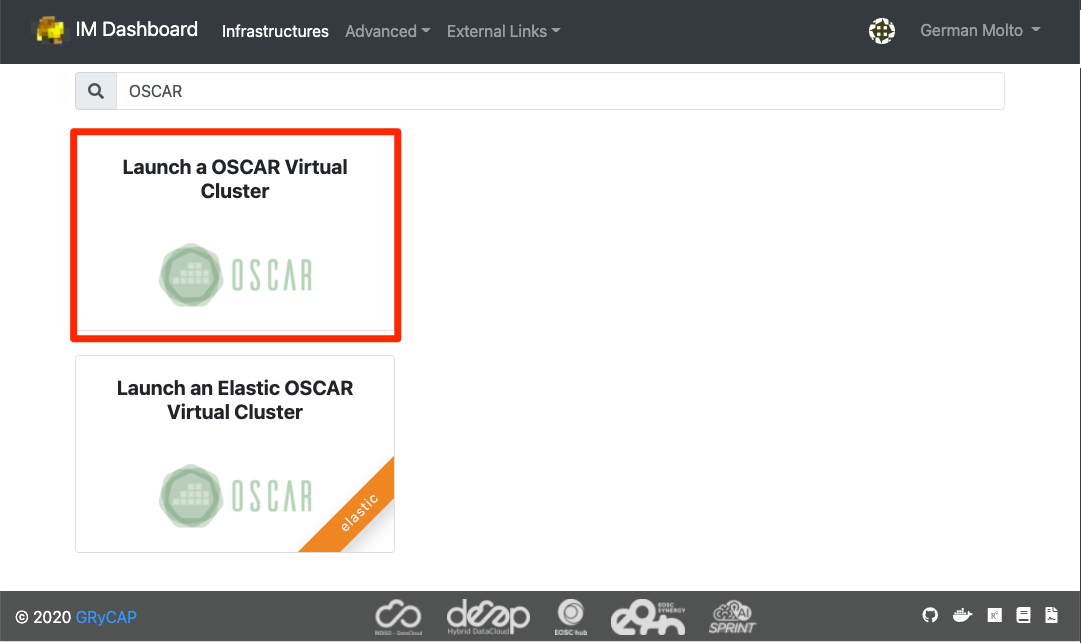
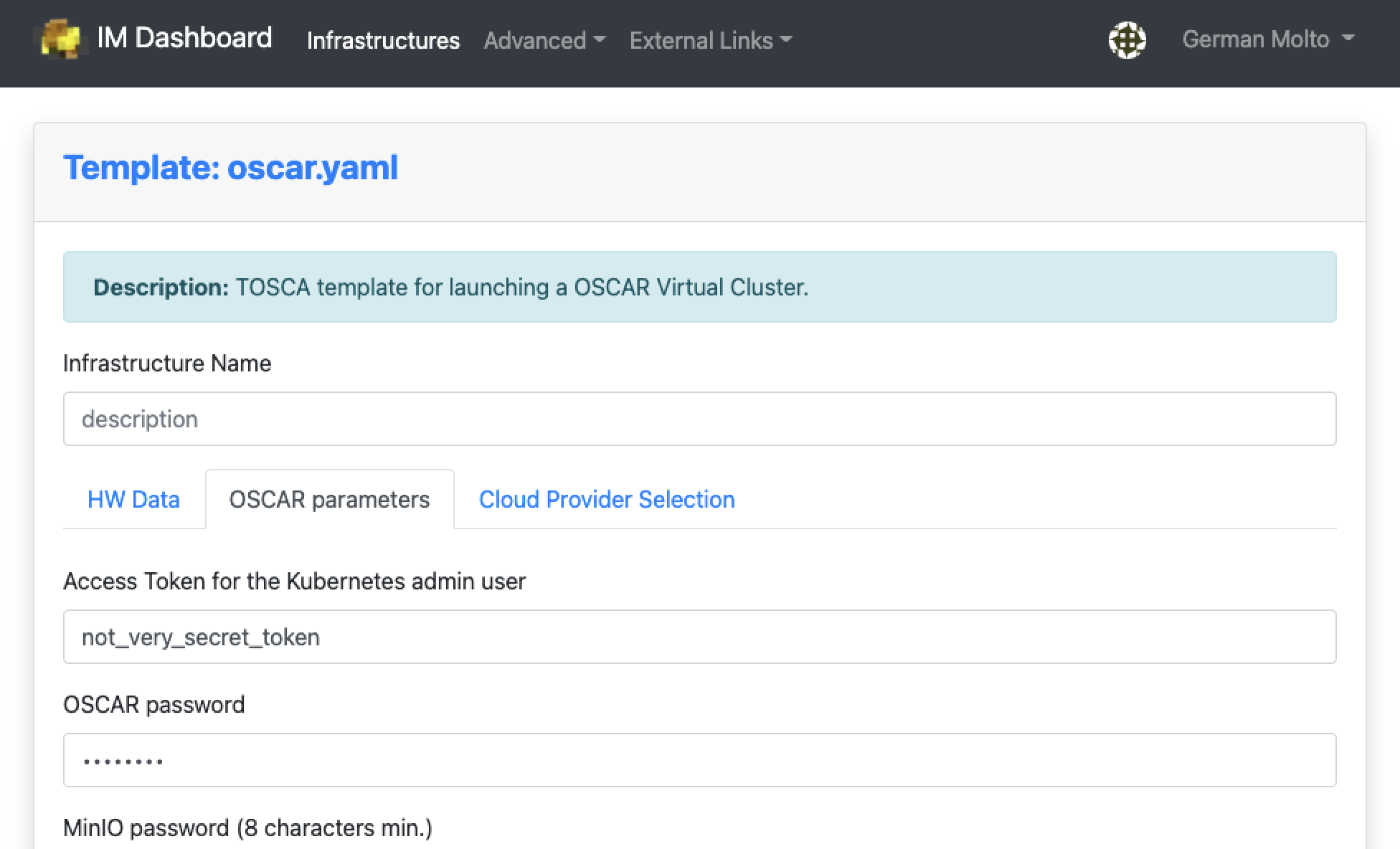
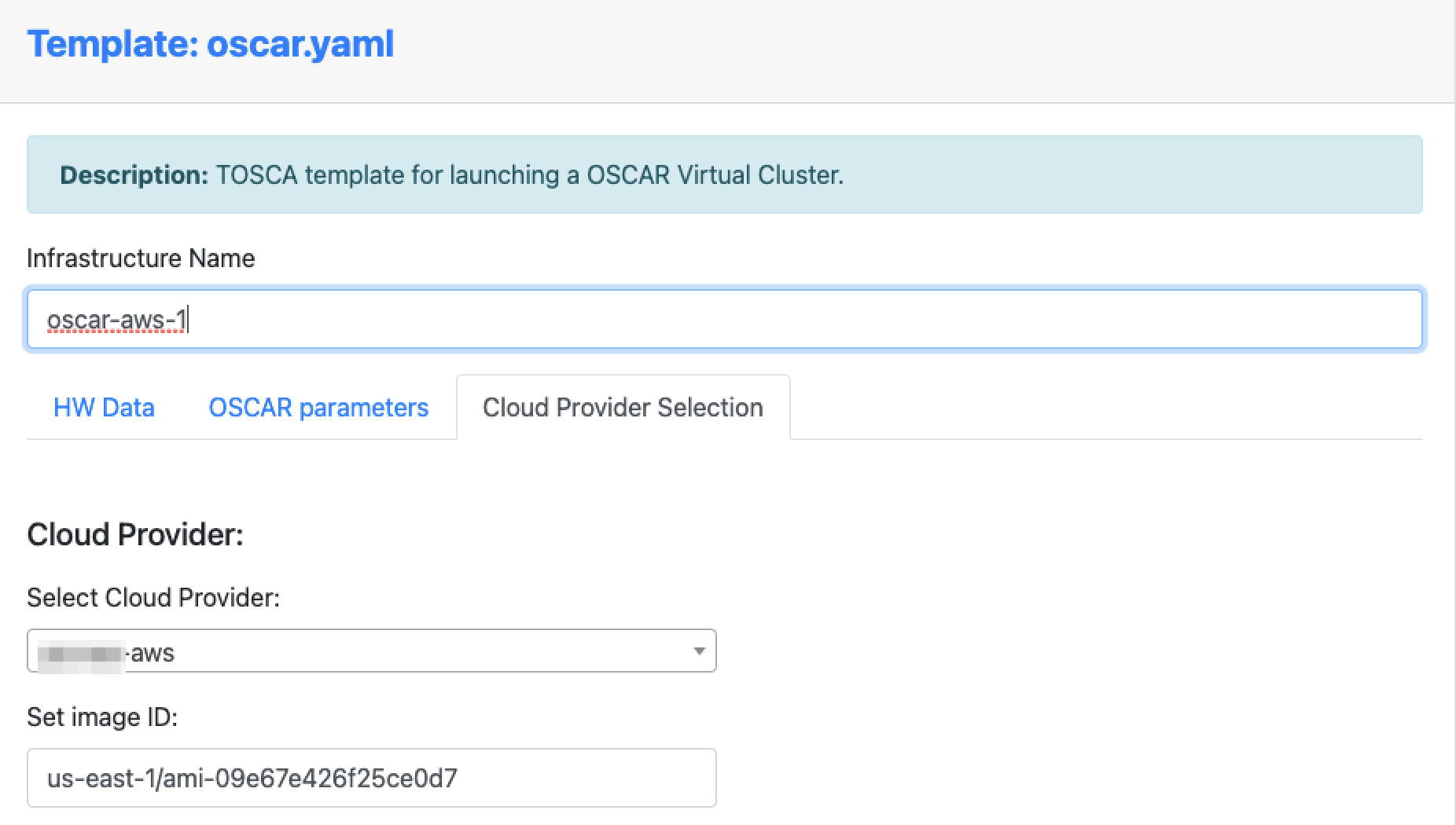
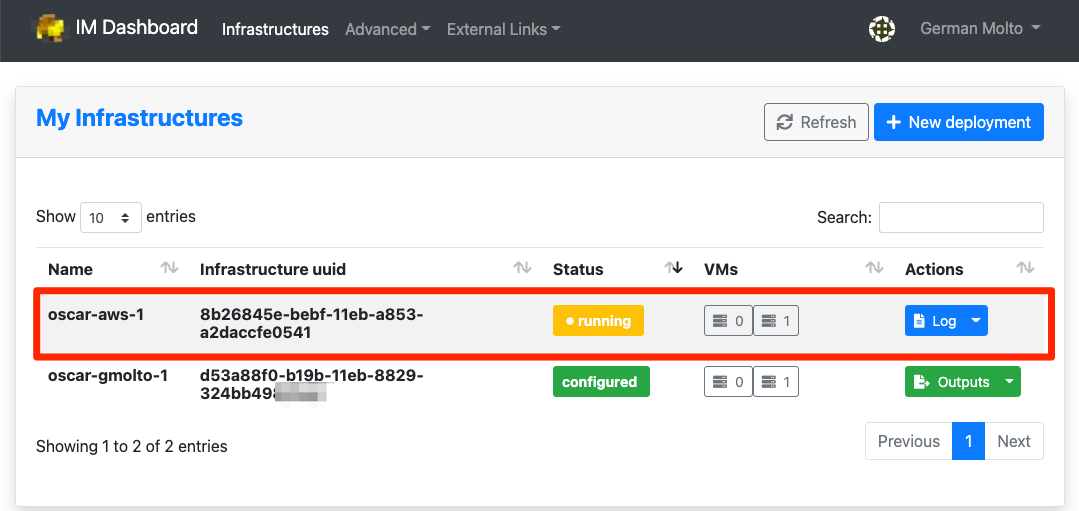
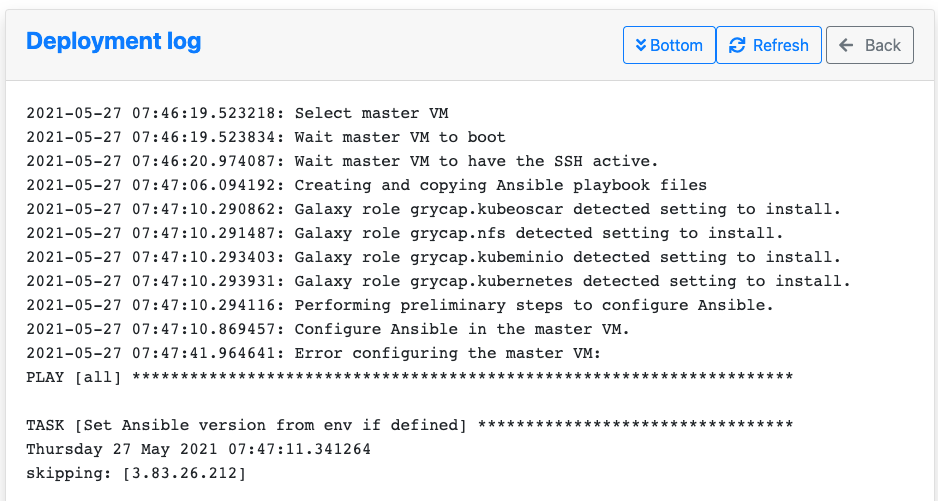
Provision OSCAR clusters through the Infrastructure Manager (IM) with a guided, streamlined workflow. From a single interface you can select your target cloud, apply deployment settings, and launch a reproducible OSCAR cluster in minutes.



OSCAR integrates with SCAR, an open-source tool for running generic applications on AWS Lambda (AWS Functions as a Service). OSCAR can also run on ARM-based edge devices such as Raspberry Pi and NVIDIA Jetson Nano boards. This enables serverless workflows across the cloud computing continuum: lightweight processing can run on-premises or at the edge, while heavier workloads run in AWS Lambda. SCAR also integrates with AWS Batch, enabling event-driven workflows for compute-intensive applications or workloads that require specialized hardware such as GPUs.

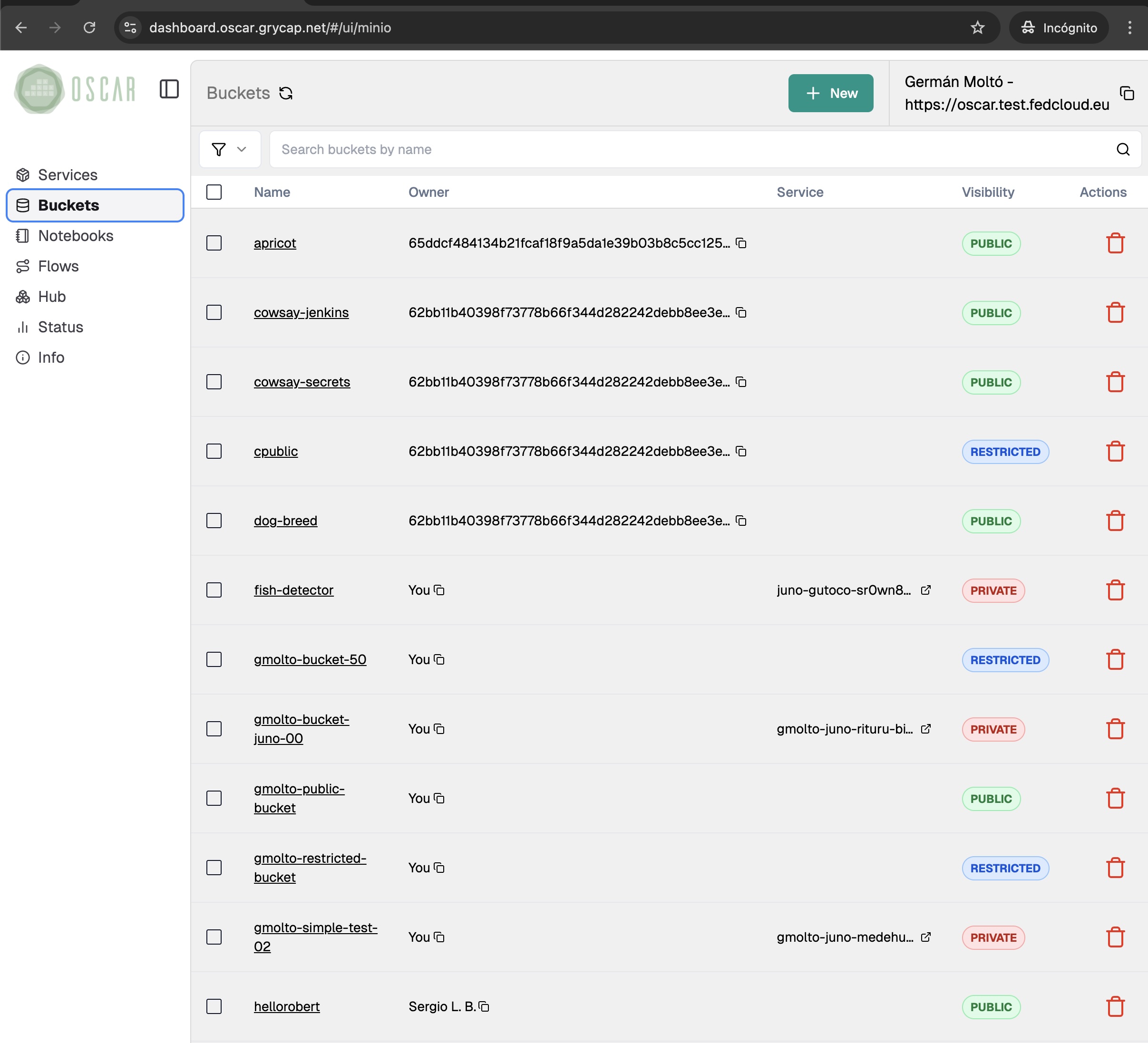
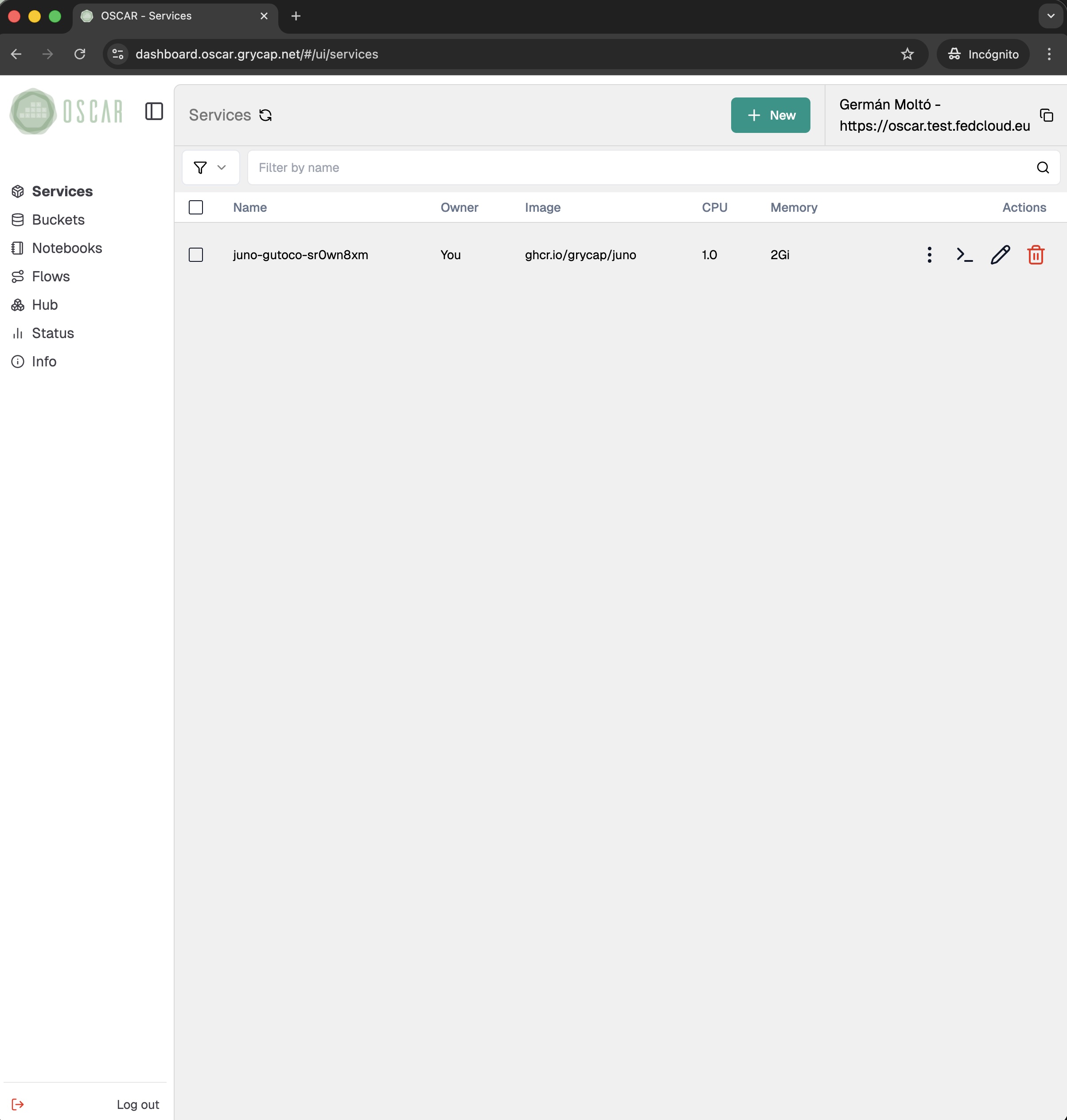
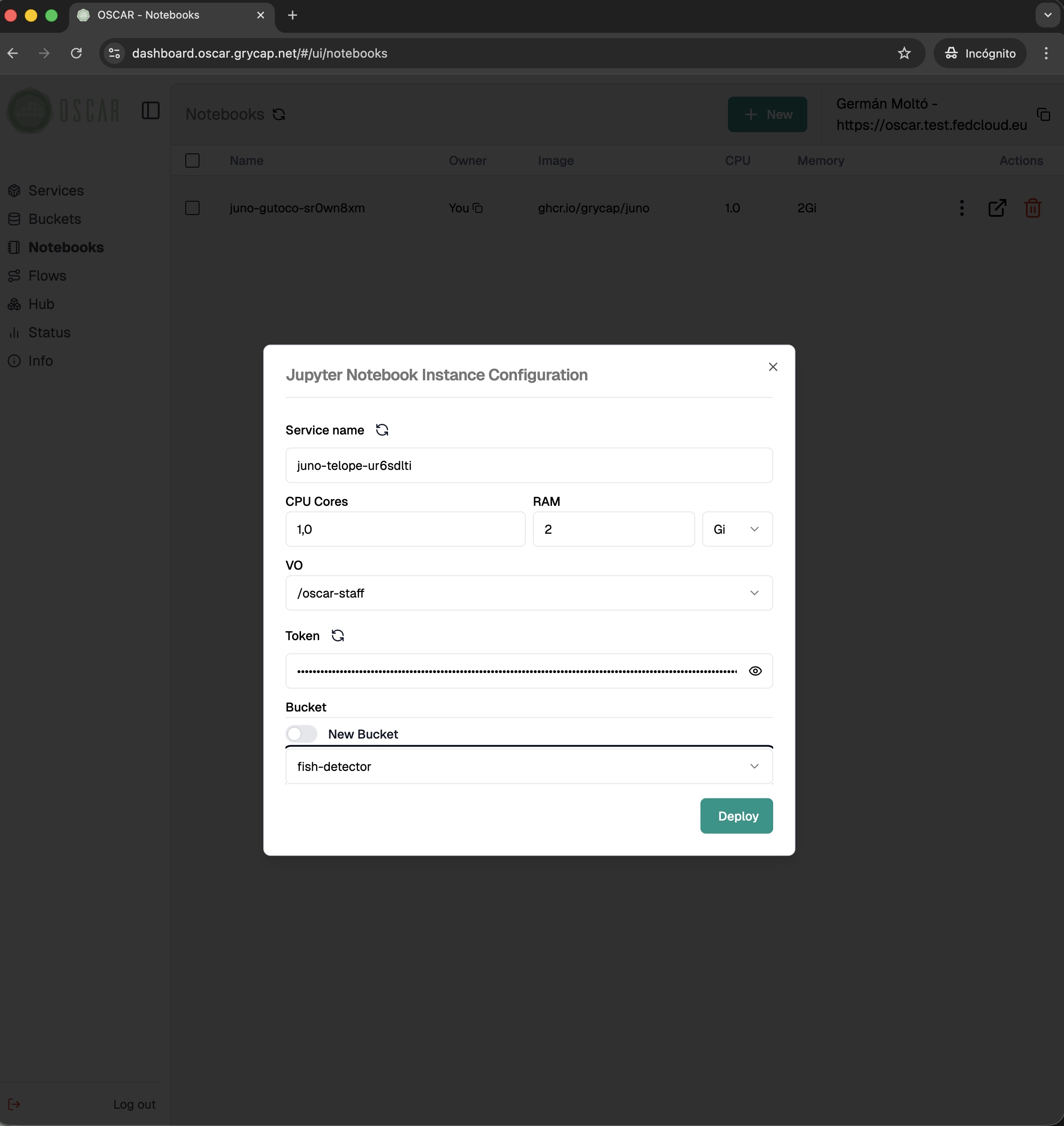
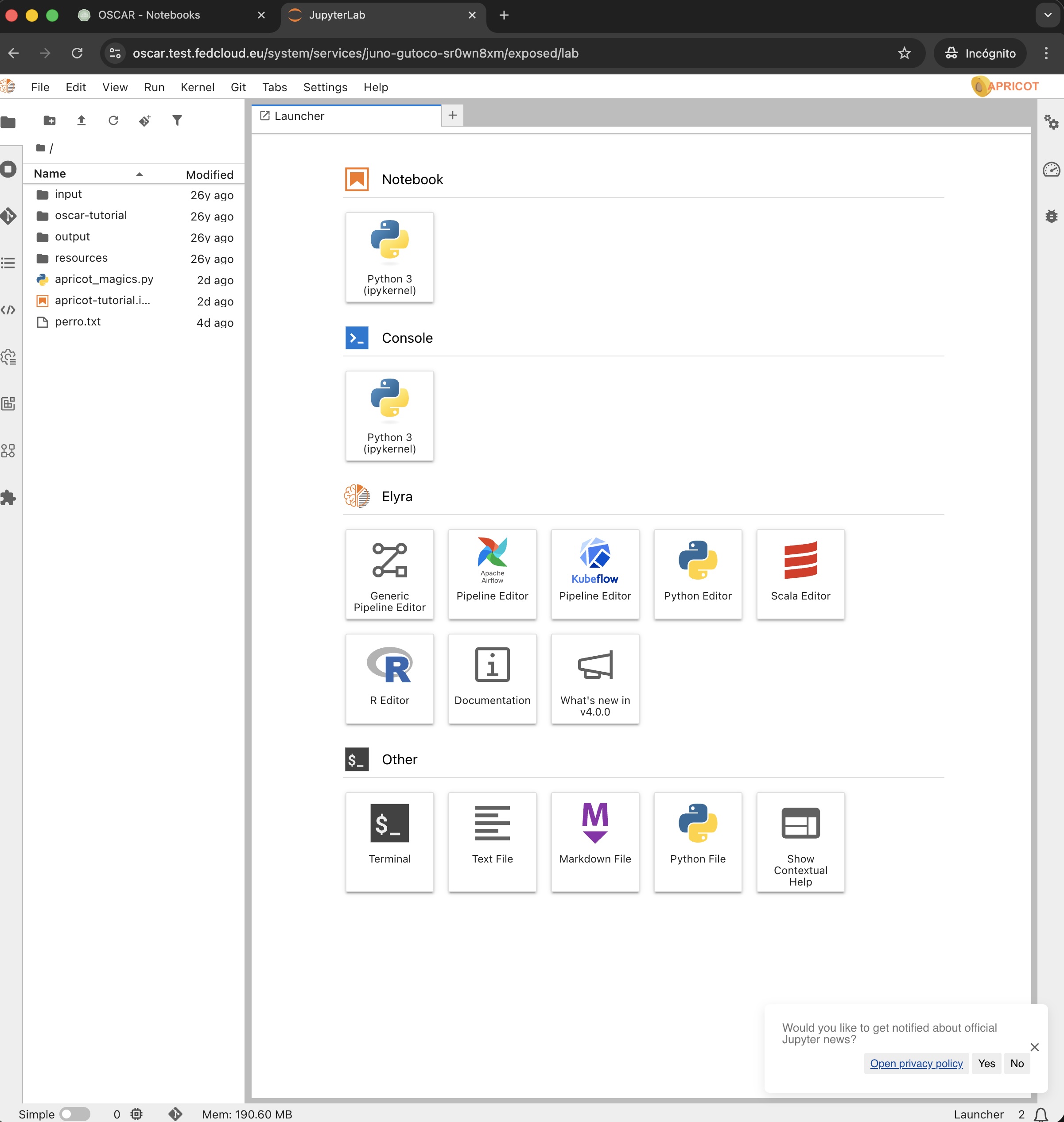
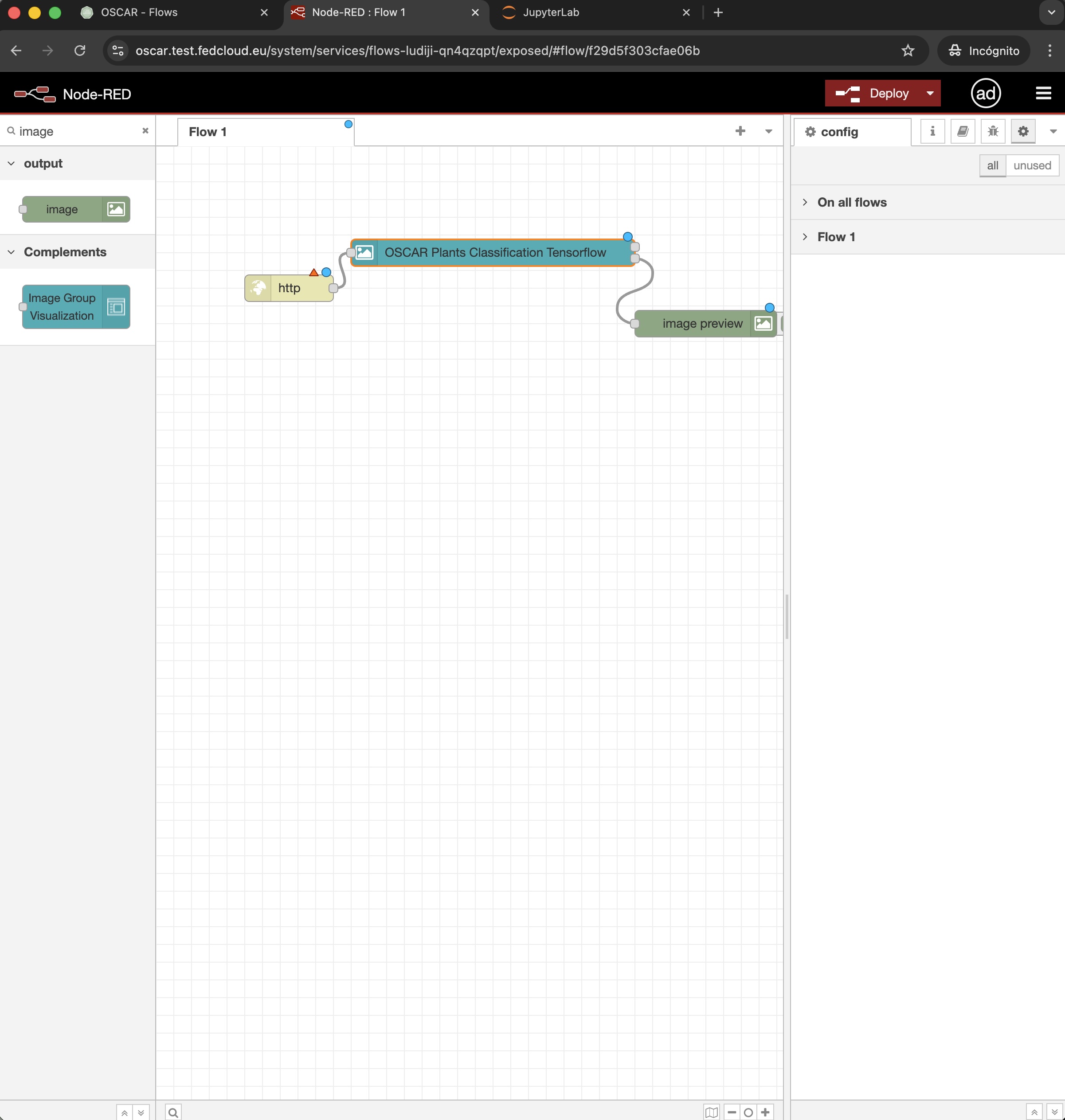
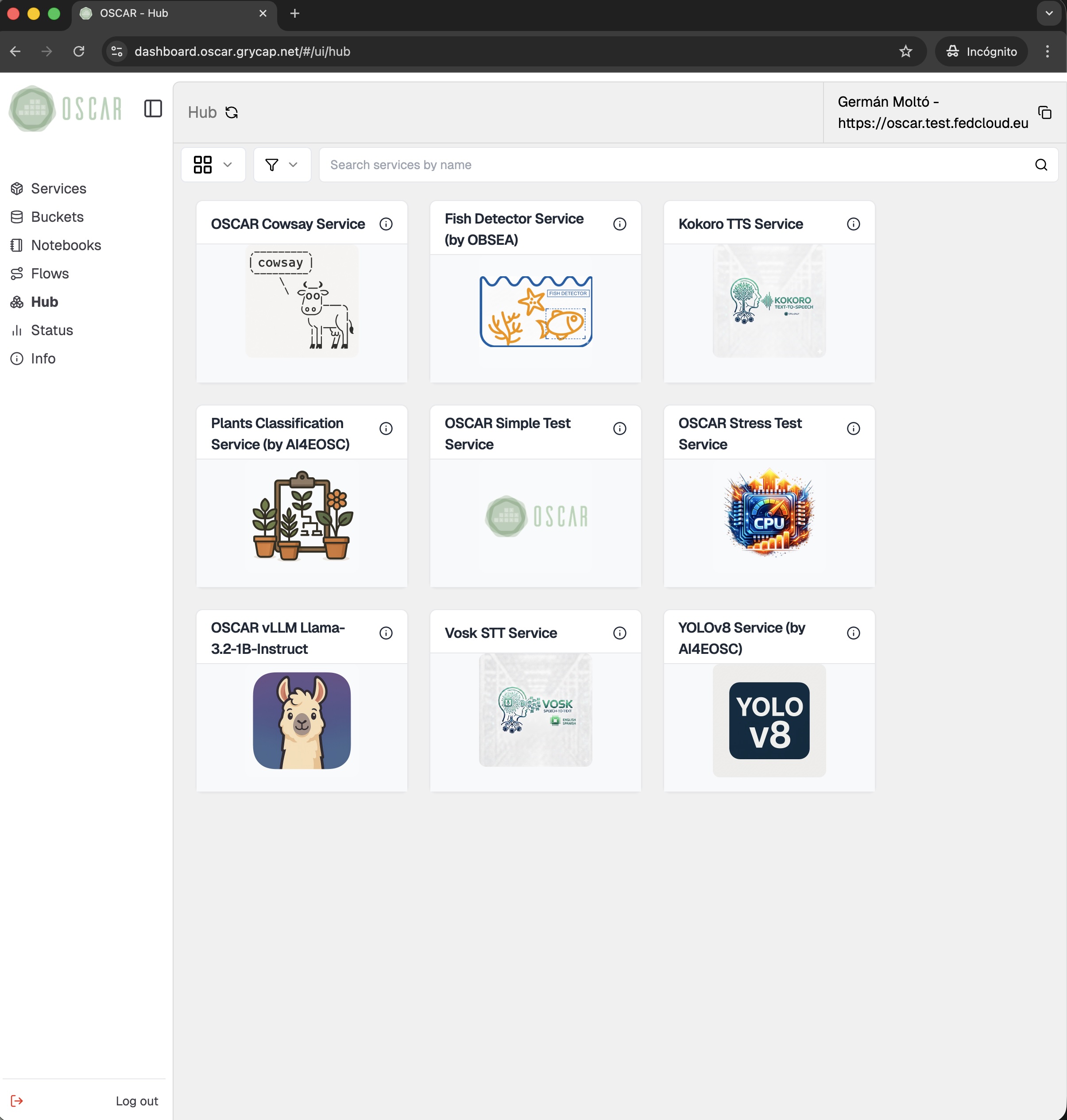
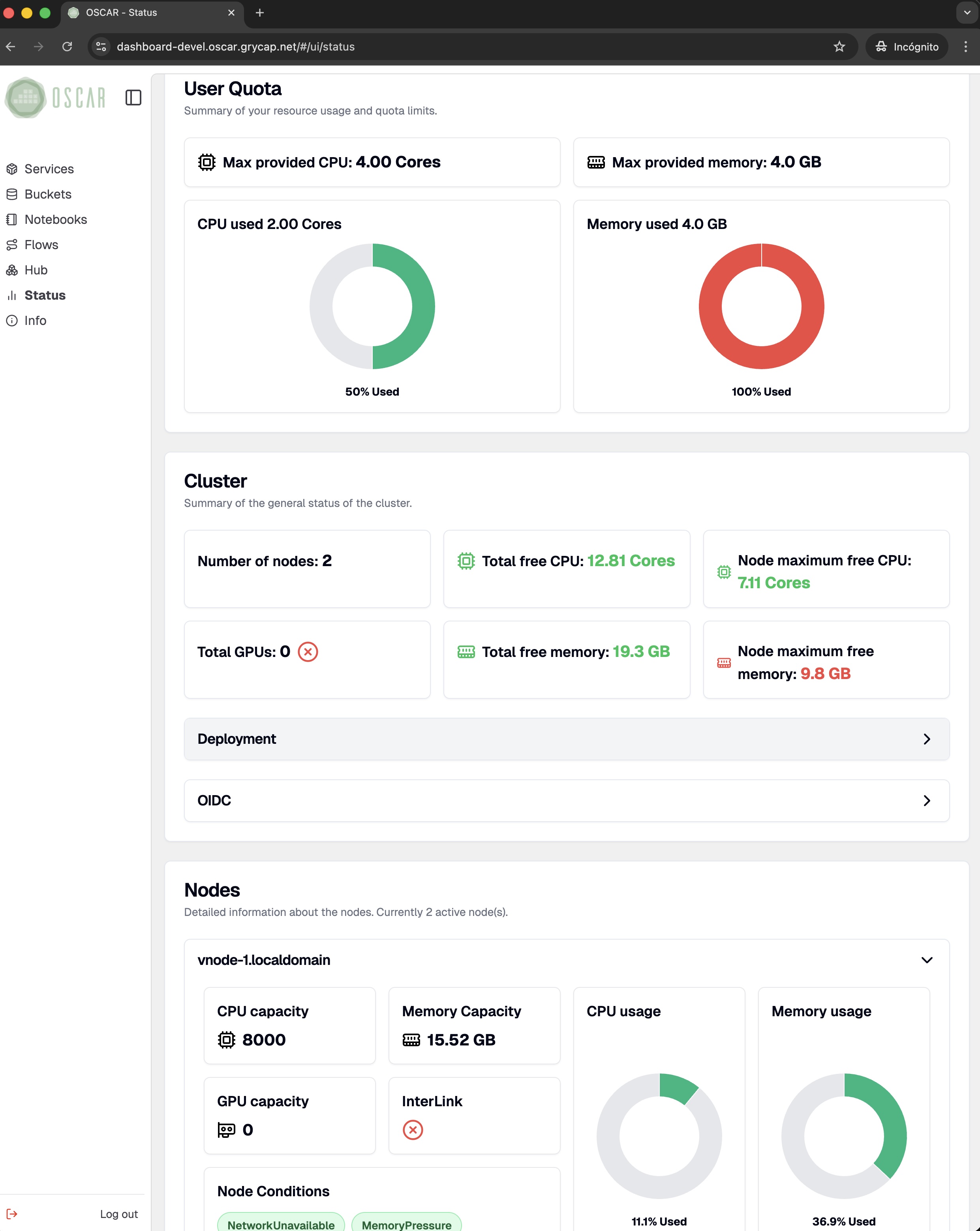
Manage the full OSCAR lifecycle from a web-based dashboard: access clusters securely, configure buckets and services, compose workflows, connect Jupyter notebook-based environments, and monitor platform status in real time.

Deploy an OSCAR cluster on your preferred cloud through the IM Dashboard. No registration is required. Not ready yet? Start with the documentation and come back when you are ready.
Deploy on a Cloud