This use case implements text-to-speech transformation using the OSCAR serverless platform, where an input of plain text returns an audio file. There are two examples of implementing this use case:
- Google Speech library
- Pretrained model of Coqui
Previous step: Deploy the OSCAR cluster on an IaaS Cloud and install OSCAR-CLI
Follow the deployment instructions with the IM Dashboard. Alternatively, the folowing script can be executed locally.
curl -sSL http://go.oscar.grycap.net | bash
To create the service, we will use the command-line interface OSCAR-CLI.
STEP 1: Deploy the Service
We will use OSCAR-CLI to deploy the use-case service. You can see all files of Google Speech and Coqui examples in GitHub.
The Google Speech example includes the following files:
- The Dockerfile to create our text-to-speech container image, using Ubuntu 20.04 as the base image and installing all the required dependencies.
- The code, implemented in Python, uses the Google Speech library to convert text to speech.
- The user script that will be executed inside the container when the service is triggered is in the file “script.sh” and will start the Python program.
- Finally, the YAML-based Functions Definition File (FDL) defines the service via oscar-cli.
The Coqui example includes the following files:
- The Dockerfile uses a base image based on Ubuntu 20.04 that installs all the dependencies.
- In this case, the bash script runs commands.
- FDL-file to deploy the services
STEP 1.1: Get the YAML file ready
Check in the YAML file that the cluster identifier is defined (OSCAR-CLI must be configured with the same cluster identifier). The “language” environment variable must be set to the language you want to hear the output voice in the Google speech library example. If you do not know the language code, it can be found here.
functions:
oscar:
- oscar-cluster:
name: text-to-speech-google
memory: 1Gi
cpu: '1.0'
image: ghcr.io/grycap/text-to-speech-google
script: script.sh
log_level: CRITICAL
input:
- storage_provider: minio
path: text-to-speech-google/input
output:
- storage_provider: minio
path: text-to-speech-google/output
environment:
Variables:
language: en
functions:
oscar:
- oscar-cluster:
name: text-to-speech-coqui
memory: 2Gi
cpu: '4.0'
image: ghcr.io/grycap/text-to-speech-coqui
log_level: CRITICAL
script: script.sh
input:
- storage_provider: minio
path: text-to-speech-coqui/input
output:
- storage_provider: minio
path: text-to-speech-coqui/output
STEP 1.2: Use OSCAR-CLI to Deploy the Service
To deploy the service, use the command:
oscar-cli apply text-to-speech-google.yaml
oscar-cli apply text-to-speech-coqui.yaml
STEP 2: Verify the Service
After some seconds, the service(s) will be created. If you specified, input and output buckets, they will be automatically created. Verify that the service(s) is up and running with the command:
oscar-cli service list

STEP 3: Invoke the Service Synchronously and Access the Output Files
To run the service synchronously, use the command:
oscar-cli service run $service_name --text-input "Hello everyone" --output output.mp3
You also can pass a text file by substituting the flag --text-input {string} to --input {filepath}
Moreover, if you have installed vlc, you can play the result. Use this one directly:
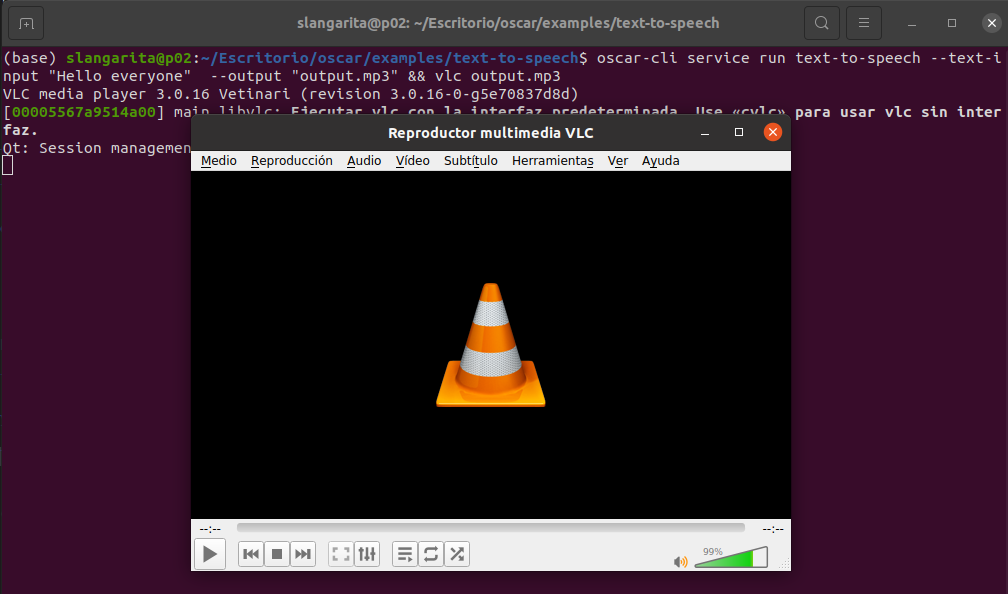
oscar-cli service run $service_name --text-input "Hello everyone" --output output.mp3 && vlc output.mp3
STEP 4: Invoke the Service Asynchronously
The service can be triggered asynchronously by uploading a text file to a MinIO bucket in text-to-speech-google/input or text-to-speech-coqui/input. When the execution finishes, the result file can be found in text-to-speech-google/output or text-to-speech-coqui/input. Input and output fields in the YAML file can be removed if we are only going to use the service synchronously.
oscar-cli service put-file text-to-speech-google $STORAGE_PROVIDER $LOCAL_FILE $REMOTE_FILE
oscar-cli service put-file text-to-speech-coqui $STORAGE_PROVIDER $LOCAL_FILE $REMOTE_FILE
STEP 4: Remove the Service
Once you have finished, the service can be deleted using the command:
oscar-cli service remove $service_name
OSCAR, IM, EC3, and CLUES are developed by the GRyCAP research group at the Universitat Politècnica de València.